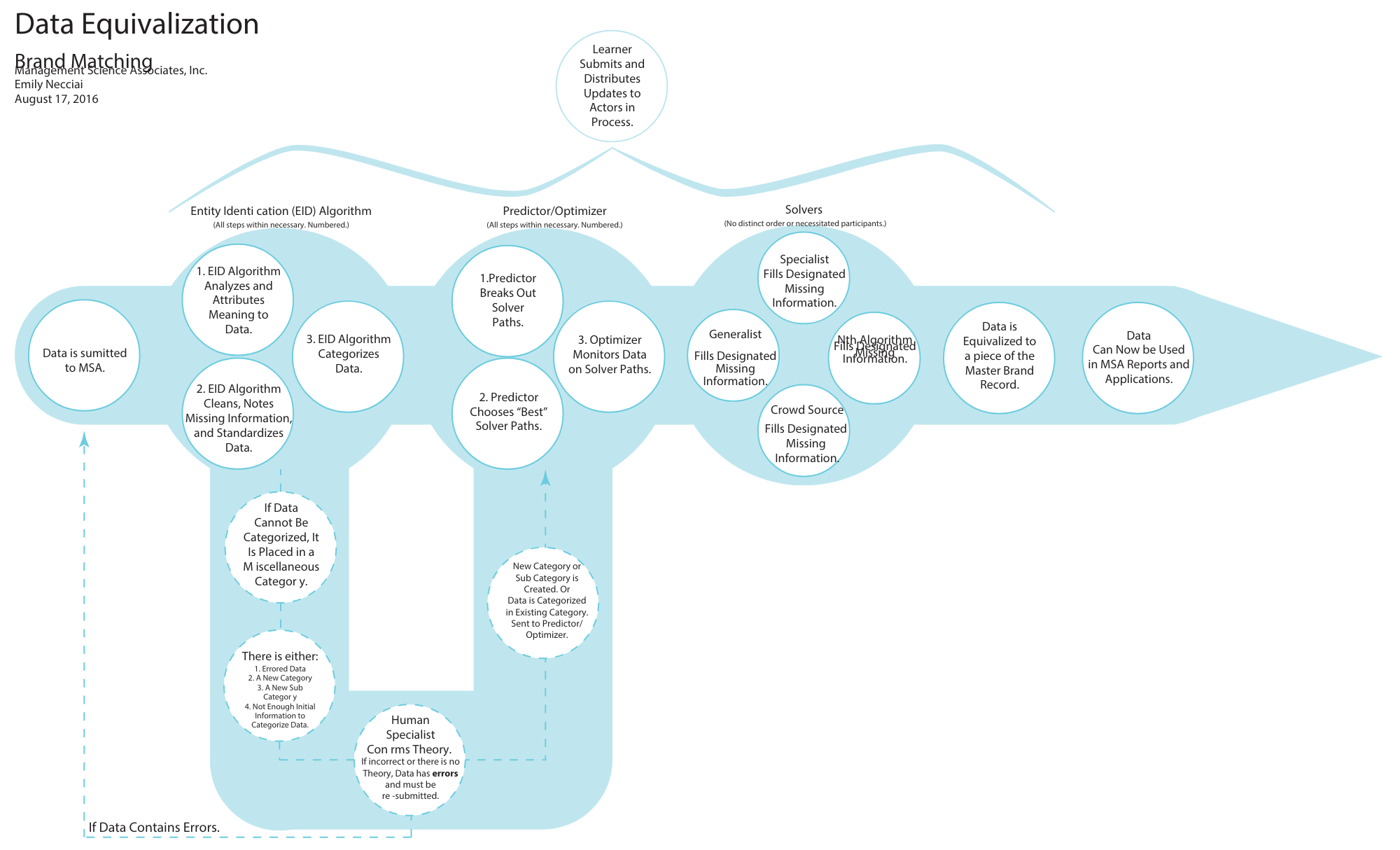
Enhancing Data Equivalization for Brand Management
This case study outlines the redesign of the Data Equivalization process at Management Science Associates, Inc. The goal was to resolve challenges in data categorization and error handling, improving the overall efficiency and accuracy of the EID (Entity Identification) Algorithm, Predictor/Optimizer functions, and Solver pathways.
Problem Statement
The existing data equivalization process faced several issues that hindered its performance:
- Complex Error Resolution: Data with errors was often miscategorized or placed in a miscellaneous category, leading to inefficiencies.
- Inadequate Categorization Algorithms: The algorithm struggled with categorizing new or incomplete data effectively.
- Manual Data Corrections: Heavy reliance on human specialists for data validation and error correction caused delays.
Objectives
- Streamline Data Categorization: Enhance the EID Algorithm to efficiently categorize and standardize data.
- Minimize Errors: Reduce the frequency of data errors requiring manual intervention.
- Improve Solver Pathway Efficiency: Ensure optimal solver paths are chosen for data correction and completion.
Methodology
Research and Analysis
- Process Mapping: Analyzed the current data flow and identified bottlenecks and redundancies in data processing.
- Stakeholder Interviews: Conducted interviews with data specialists and users to gather insights on pain points and improvement areas.
Key Findings
- The EID Algorithm needed improvements in cleaning and standardizing data efficiently.
- A lack of automated solutions for filling missing data increased the dependency on human specialists.
- Existing categories were insufficient to handle the diversity of data inputs.
Design Solutions
1. Enhanced EID Algorithm
- Advanced Data Cleaning: Improved algorithms for cleaning data and identifying missing elements automatically.
- Dynamic Categorization: Developed a more flexible categorization system that updates with new data types and sub-categories.
2. Predictor/Optimizer Improvements
- Optimized Solver Paths: Integrated machine learning techniques to choose the "best" solver paths quickly and accurately.
- Automated Monitoring: Implemented real-time monitoring to preemptively identify and resolve potential data issues.
3. Solver Enhancements
- Nth Algorithm Updates: Enabled the Nth Algorithm to fill in missing information, reducing reliance on manual input.
- Crowdsourcing Integration: Leveraged crowdsource solutions to fill in gaps and verify data when applicable.
Outcomes
- Increased Accuracy: Enhanced data accuracy and reduced error rates through improved algorithms and processes.
- Efficiency Gains: Significantly decreased time spent on manual data correction and validation.
- Robust Data Classification: Enabled better handling of new data categories and more accurate data equivalization.
Reflections and Future Directions
- User Feedback Loop: Continuous feedback from data specialists proved vital in refining the algorithms and processes.
- Scalable Solutions: Future enhancements may include further automation of tasks and integration of advanced AI models for prediction and categorization.
This project successfully addressed critical inefficiencies in the data equivalization process, resulting in improved data quality and streamlined operations for brand management reporting.